Last updated: 2026-05-22
Overview
Freddy AI Copilot impact reports give service desk administrators and managers a centralized framework for measuring the strategic value of AI across their helpdesk operations. The reports convert raw usage data into actionable business key performance indicators (KPIs) and time saved, enabling you to communicate operational effectiveness to stakeholders and leadership.
In this article, learn how to read and act on each of the six reporting tabs in the Freddy AI Copilot reporting suite.
What you can do with these reports
Reporting tabs
The reporting suite is organized into six specialized views. Each tab answers a distinct business question:
| Summary | How is AI performing at a glance? What are my top KPIs and who are my AI champions? |
| Adoption | How deeply is AI being used across agents and tickets? Where are the gaps? |
| Impact | Is AI improving SLA compliance and satisfaction scores? What does the cohort data show? |
| Breakdown of Features | Which individual AI tools are being accepted or rejected? Where is training needed? |
| Feature Usage (With Feedback) | Which AI features are agents actually using, and do they like them? Track acceptance rates and feedback signals side-by-side. |
| Feature Usage (Without Feedback) | How accurately and efficiently are individual AI features operating? Dive into generation counts, assignment rates, and acceptance benchmarks by feature. |
Summary tab
The Summary tab provides an executive-level overview of your AI deployment and its immediate effect on helpdesk productivity. Use this tab to report high-level ROI to stakeholders and to identify internal AI champions who are most efficient with the toolset.
View aggregate performance
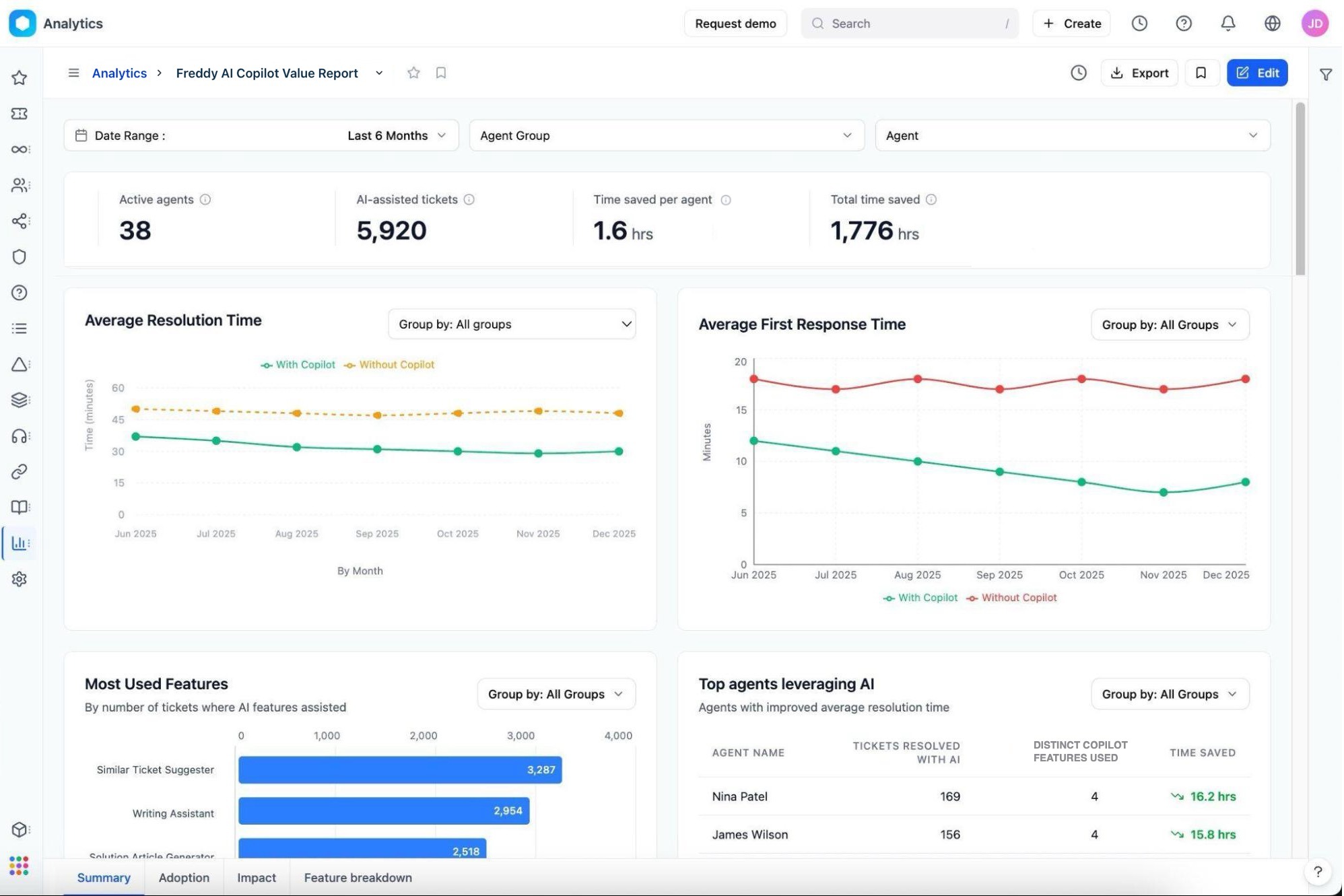
The top row of the dashboard displays cumulative KPI widgets that quantify the immediate footprint of AI in your service desk.
Key metrics in the table
| Active agents | Number of agents who used at least one Freddy AI feature in the selected date range. The percentage change indicator compares the current period to the previous period. |
| AI-assisted tickets | Total tickets where an agent invoked at least one Copilot feature. Use this as your primary volume benchmark for AI utilization. |
| Time saved per agent | Average time reclaimed per agent through AI assistance. Multiply by the hourly rate to calculate per-agent cost savings. |
| Total time saved | Aggregate productivity reclaimed across the entire service desk for the selected period. |
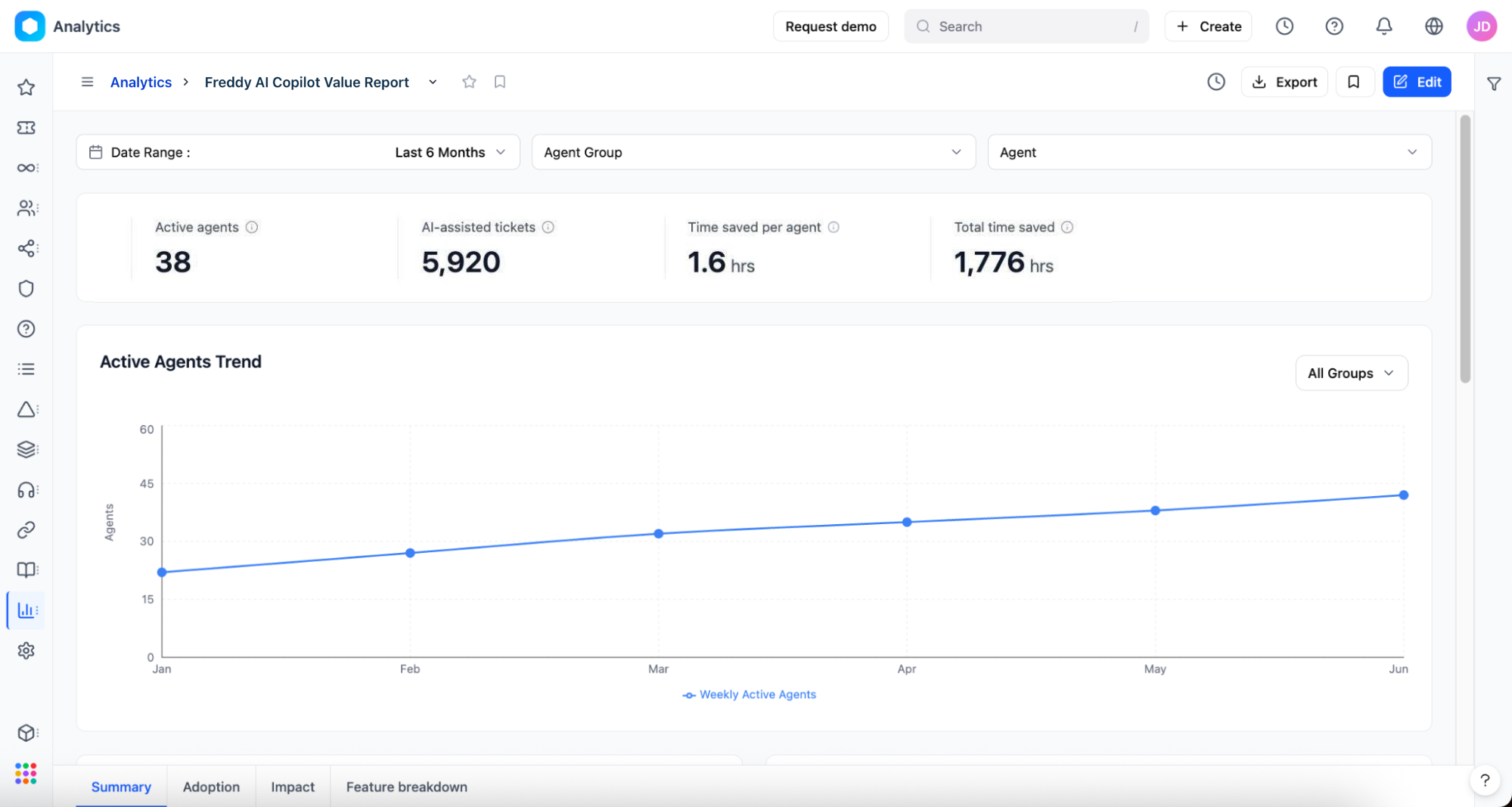
``` The Active Agents Trend line chart plots the count of agents using Copilot features. An upward slope confirms that AI adoption is growing organically. A plateau or decline warrants investigation using the Adoption tab. ```
Compare performance trends
The Average Resolution Time and Average First Response Time line charts track helpdesk efficiency over time. Both charts use the same two-line convention:
| Solid green line | Tickets where at least one Freddy AI feature was used (With Copilot). |
| Dashed orange/red line | Tickets handled without any AI assistance (Without Copilot baseline). |
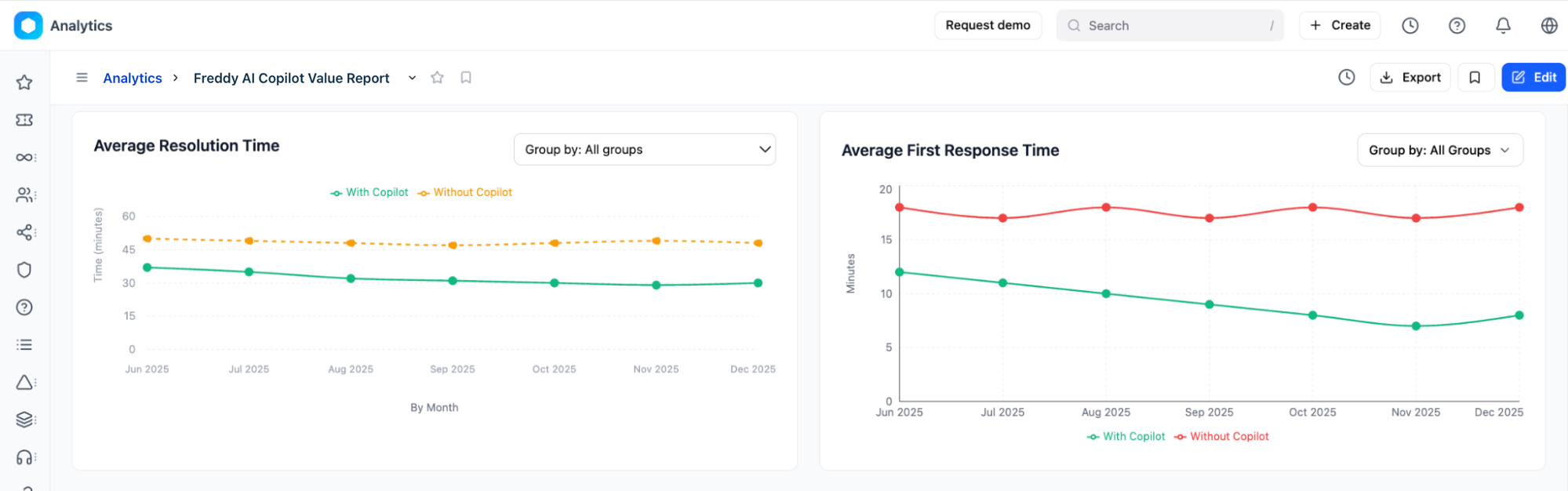
How to interpret the trend charts
Most Used Features
The Most Used Features horizontal bar chart ranks each Freddy AI capability by the number of tickets it assisted. The x-axis represents ticket count; longer bars indicate higher adoption for that feature.
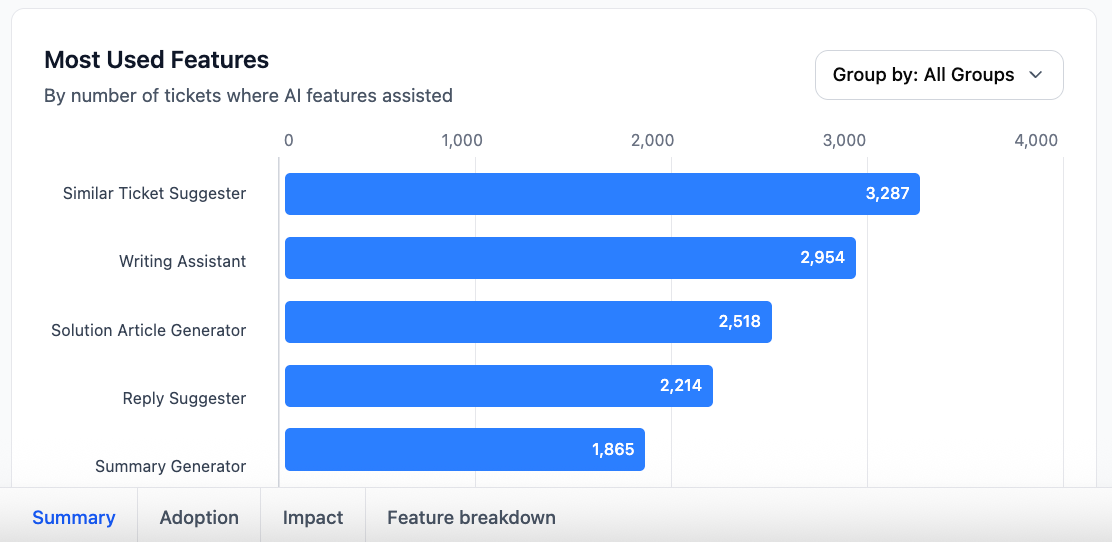
How to interpret the chart
Top agents leveraging AI
The Top agents leveraging AI table identifies individual contributors who most effectively integrate Copilot into their resolution workflows. These agents serve as measurable AI champions.
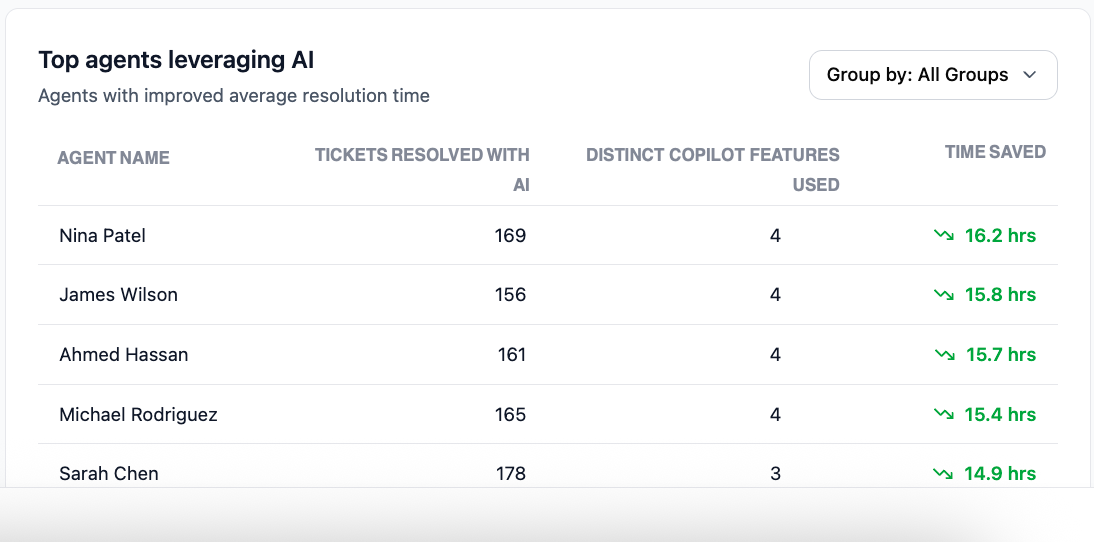
Key metrics in the table
| Tickets Resolved with AI | Total tickets closed in which the agent used at least one Copilot feature. High counts validate consistent AI engagement. |
| Distinct Copilot Features Used | Total number of unique AI features invoked per ticket. A higher value (for example, 4) indicates comprehensive suite adoption rather than reliance on a single tool. |
| Time Saved | Total hours reclaimed by the agent compared to their own manual baseline. |
How to use this data
Adoption tab
The Adoption tab measures the depth and breadth of AI integration across your support teams. Use this tab to identify friction points in your rollout, track seat utilization, and set data-driven targets for onboarding programs.
Ticket Overview
The Ticket Overview section gives you a snapshot of how broadly Freddy AI is touching your support volume. Use these metrics to assess overall AI saturation before drilling into team-level breakdowns.
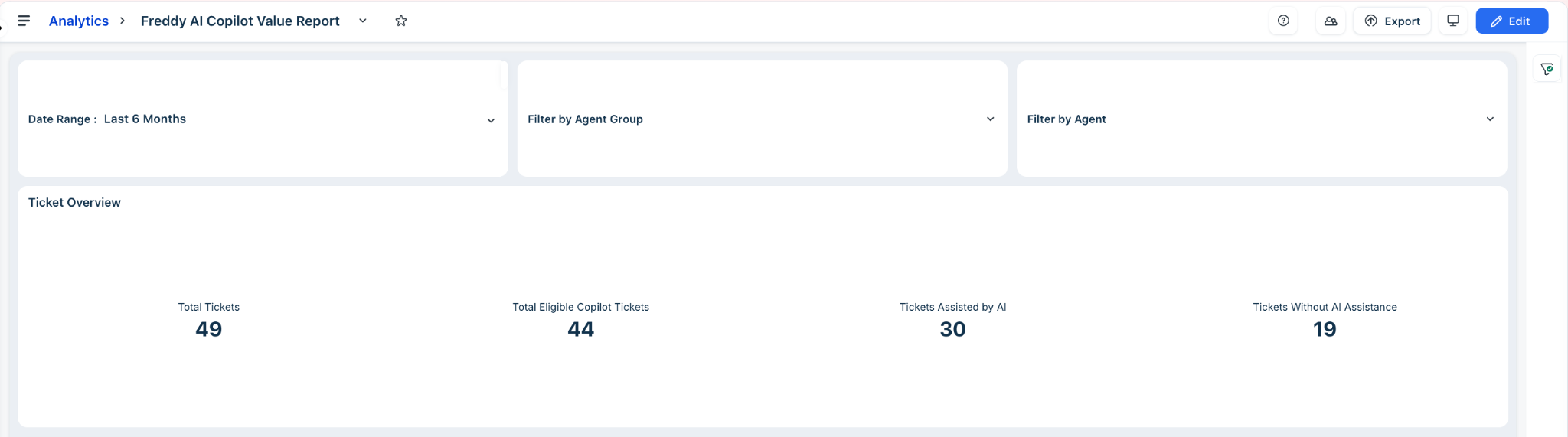
Key metrics in the table
| Metric | What it means |
| Total Tickets | All tickets received in the selected date range. This is your baseline for understanding the scale of support operations during the period. |
| Total Eligible Copilot Tickets | Total Eligible Copilot Tickets where your Copilot agents were assigned and able to assist. This represents your current AI coverage — expanding it through additional licenses and broader agent assignment directly increases the value you capture from AI-powered support. |
| Tickets Assisted by AI | Tickets where an agent actively used at least one Copilot feature. The ratio of this to Total Eligible Copilot Tickets is your AI Assistance Rate — the headline adoption metric for executive reporting. |
| Tickets Without AI Assistance | Eligible tickets where no AI feature was used — your unrealized opportunity. A declining count here signals that AI is becoming a consistent part of the standard resolution workflow rather than an occasional tool. |
AI Adoption by Tickets
The AI Adoption by Tickets table breaks down ticket volume and AI assistance per agent group, helping you pinpoint which teams are driving AI-assisted resolutions and which are lagging.
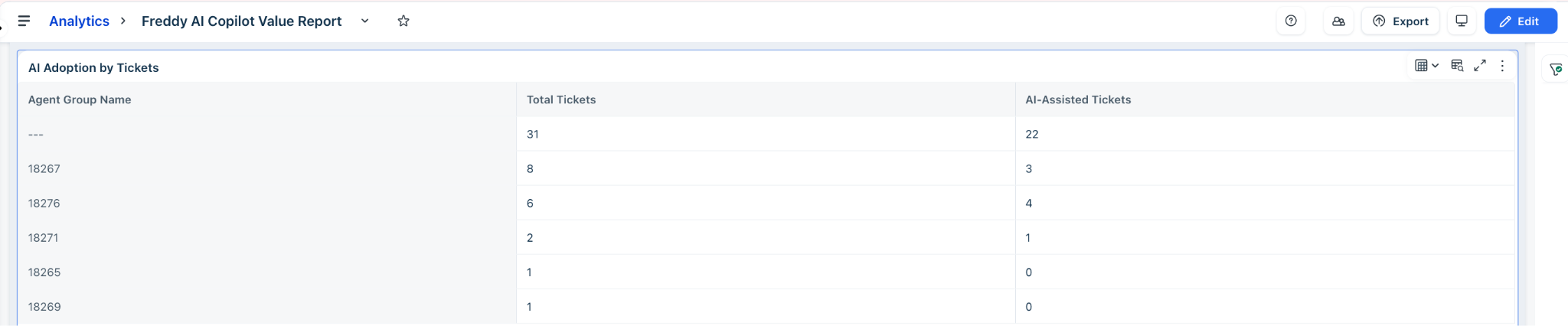
Key metrics in the table
| Column comparison | What to look for | Action |
| Total Tickets vs. AI-Assisted Tickets | Calculate a team-specific AI Assistance Rate per group | Groups with a low ratio despite high ticket volume are your highest-impact enablement targets — small behavior changes here will move your overall adoption number significantly |
AI Adoption by Agents
The AI Adoption by Agents table shifts the lens from tickets to people, showing how many agents within each group are actively engaging with Copilot and how productive they are.

Key metrics in the table
| Column comparison | What to look for | Action |
| Active AI Users vs. Total Users | Teams approaching 100% show strong buy-in | Use high-adoption teams as internal champions; investigate low-ratio teams for workflow blockers, insufficient awareness, or onboarding gaps |
| Avg Tickets Handled — All Users vs. AI Users | AI Users handling higher average volume than all users in the same group | Validates efficiency gains for that team and strengthens the business case for expanding Copilot access |
``` Tip: Sort the AI Adoption by Agents table by Active AI Users to immediately surface teams with the lowest engagement. For groups where Active AI Users represent less than 50% of Total Users, schedule a dedicated enablement session and follow up directly with agents showing zero usage. ```
Impact tab
The Impact tab correlates AI usage with your critical service level agreements (SLAs) and satisfaction scores. This strategic view demonstrates that AI assistance not only saves time but also improves service quality and resolution accuracy.
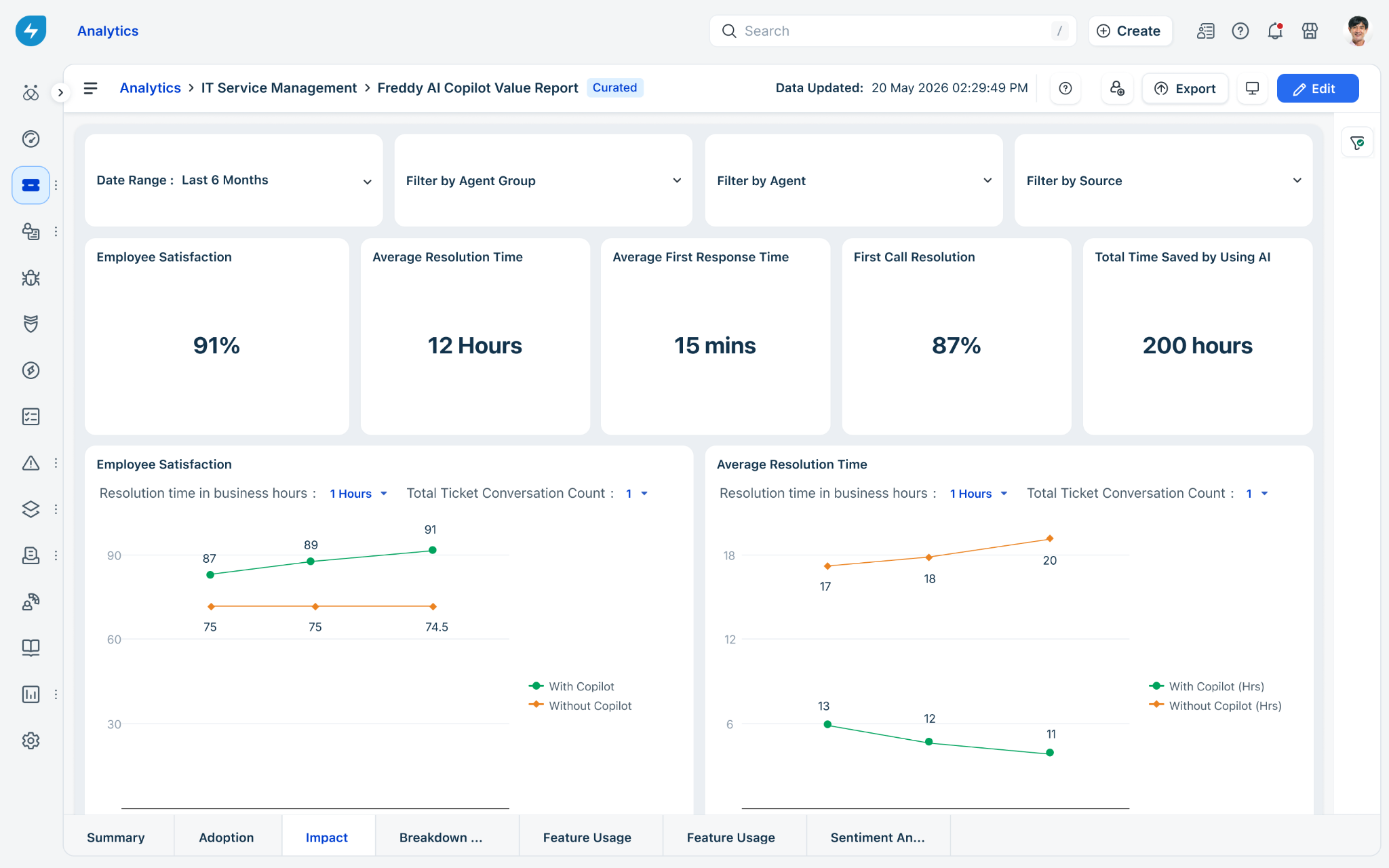
Use ticket resolution metrics to build the business case for AI investment and identify where Copilot is delivering the most value.
``` Note: if metrics aren't trending the intended way, it doesn't necessarily mean Copilot isn't working. It could signal an adoption gap, or that agents are routing Copilot toward more complex tickets where resolution naturally takes longer. Worth segmenting by ticket complexity and usage frequency before drawing conclusions. ```
Top-line KPIs
These metrics give you an at-a-glance view of AI's operational impact — track them over time to quantify efficiency gains and surface areas where Copilot is underperforming.

Key metrics in the table
| Metric | What it means |
| Avg Resolution Time | Average time taken to fully resolve a ticket. A declining trend in AI-assisted tickets indicates that Copilot is helping agents close issues faster. |
| Avg First Response Time | Average time before an agent sends the first reply. Lower values signal that AI suggestions are helping agents respond to customers more quickly. |
| First Call Resolution | Percentage of tickets resolved in a single interaction. An upward trend suggests AI is helping agents arrive at the right answer sooner, without back-and-forth. |
| Total Time Saved by Using AI | Cumulative hours reclaimed across all agents as a result of AI assistance — your headline efficiency metric for executive and finance reporting. |
Average Resolution Time
How is Copilot affecting the time it takes to close tickets? This chart plots resolution time for AI-assisted tickets against non-assisted tickets over the selected period, making the productivity delta immediately visible.
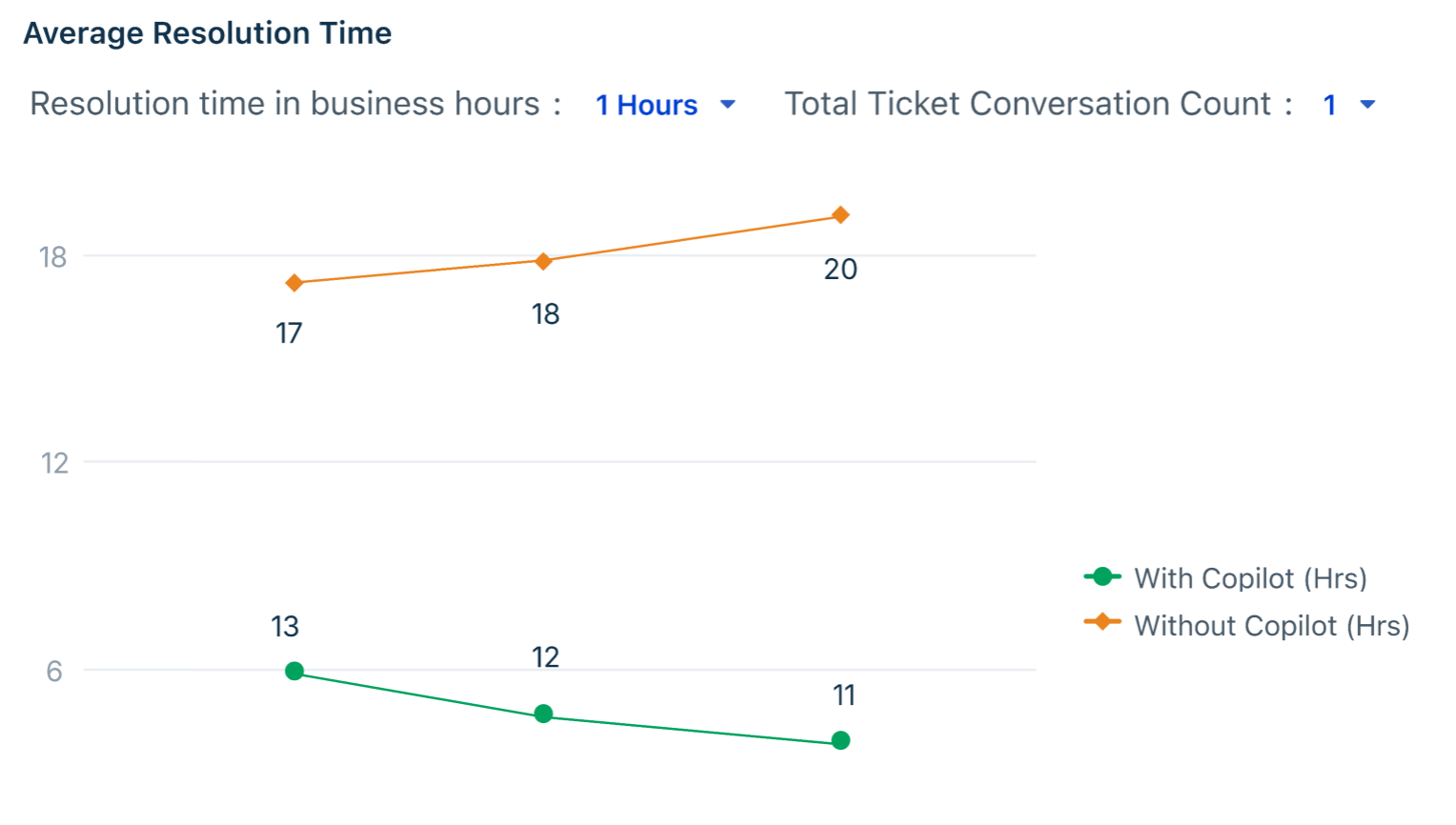
Key metrics in the table
| What to look for | Why it matters |
| With Copilot trending below Without Copilot | Confirms that AI assistance is directly contributing to faster resolutions — the core efficiency argument for Copilot adoption. |
| Gap widening over time | Indicates that agents are becoming more proficient with AI tools, compounding efficiency gains as adoption matures. |
| Lines converging or crossing | Warrants investigation — agents may be over-relying on AI suggestions without review, or the ticket mix may have shifted toward more complex issues. |
Average First Response Time
Is AI helping agents reply to customers faster? This chart compares first response time between AI-assisted and non-assisted tickets, surfacing whether Copilot features like Reply Suggester are reducing the time customers wait for an initial reply.
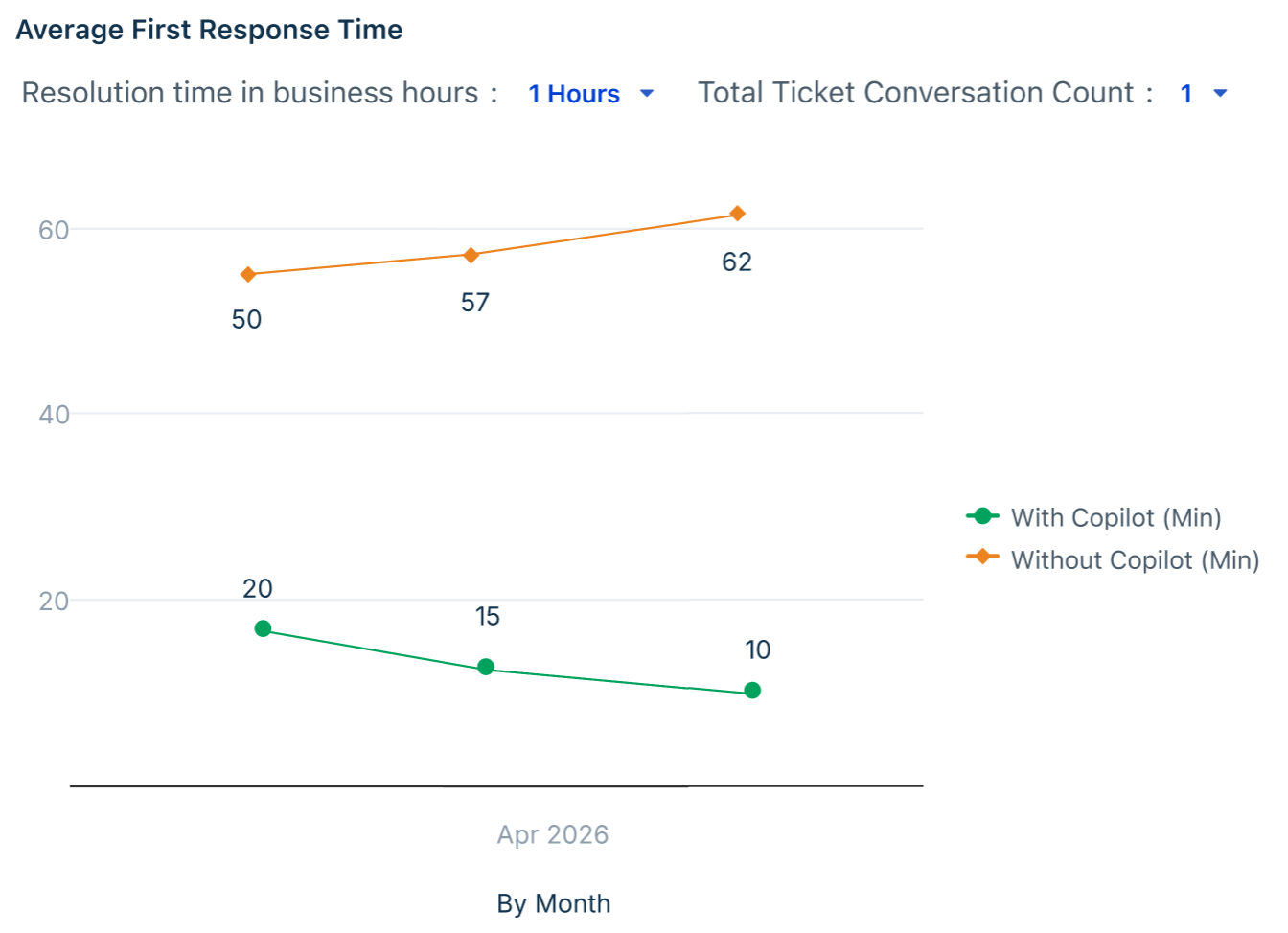
Key metrics in the table
| What to look for | Why it matters |
| With Copilot trending below Without Copilot | Validates that AI suggestions are reducing the time agents spend crafting initial responses, directly improving the customer experience. |
| Sharp early drop in the With Copilot line | Suggests a cohort of highly engaged agents driving outsized gains — identify them and replicate their workflows across the team. |
| Without Copilot line dropping to zero | May indicate that non-AI-assisted tickets are being resolved or abandoned rather than replied to — cross-reference with ticket closure data to confirm. |
``` Tip: Use the Resolution Time in Hours and Total Ticket Conversation Count filters on each chart to control for ticket complexity. High-conversation tickets naturally take longer to resolve — isolating low-conversation tickets gives you a cleaner read on AI's direct impact on resolution speed. ```
First Call Resolution
Are agents resolving issues in a single interaction when using Copilot? This chart compares the FCR rate between AI-assisted and non-assisted tickets, revealing whether Copilot is helping agents arrive at the right answer without requiring follow-up conversations.
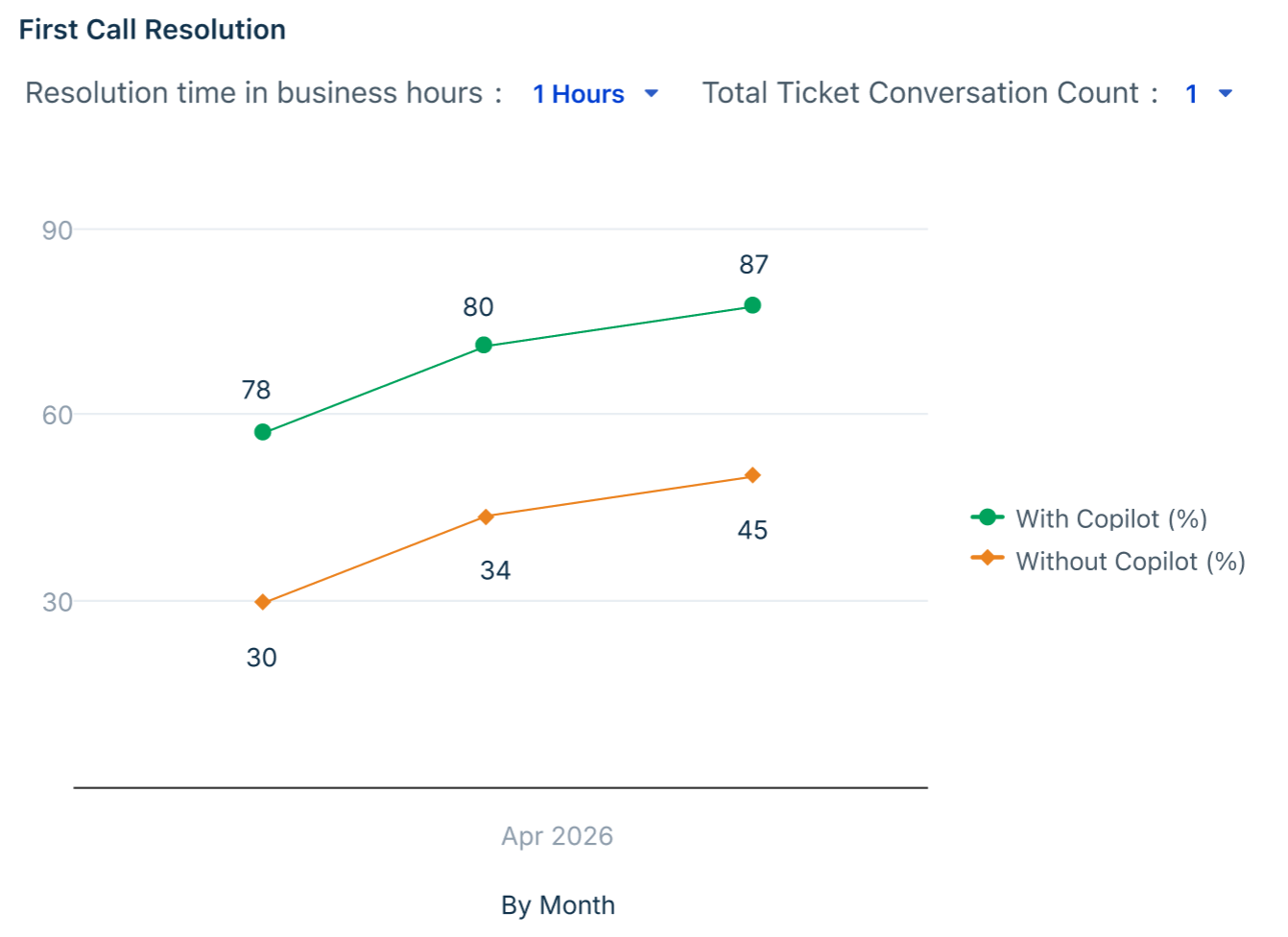
Key metrics in the table
| What to look for | Why it matters |
| With Copilot FCR rate higher than Without Copilot | Confirms that AI context — such as similar ticket suggestions and knowledge base insights — is helping agents resolve issues completely on the first attempt. |
| Without Copilot holding at 0% | Indicates that tickets handled without AI assistance are rarely resolved in a single interaction, strengthening the case for consistent Copilot usage across all eligible tickets. |
| With Copilot rate growing month over month | Signals that agents are becoming more effective at leveraging AI to diagnose and resolve issues faster, reducing the back-and-forth that drives up conversation counts. |
``` Tip: Use the Resolution Time and Total Ticket Conversation Count filters to isolate specific ticket complexity bands. FCR rates are naturally lower for complex, multi-conversation tickets — filtering to simpler tickets gives you a cleaner signal of AI's direct contribution to first-touch resolution. ```
Breakdown of Features
This tab shifts the focus from overall AI performance to individual feature-level behavior, showing which tools agents are using, how frequently, and how much time each is saving. Use this view to identify training gaps, surface power users, and prioritize enablement efforts by feature.
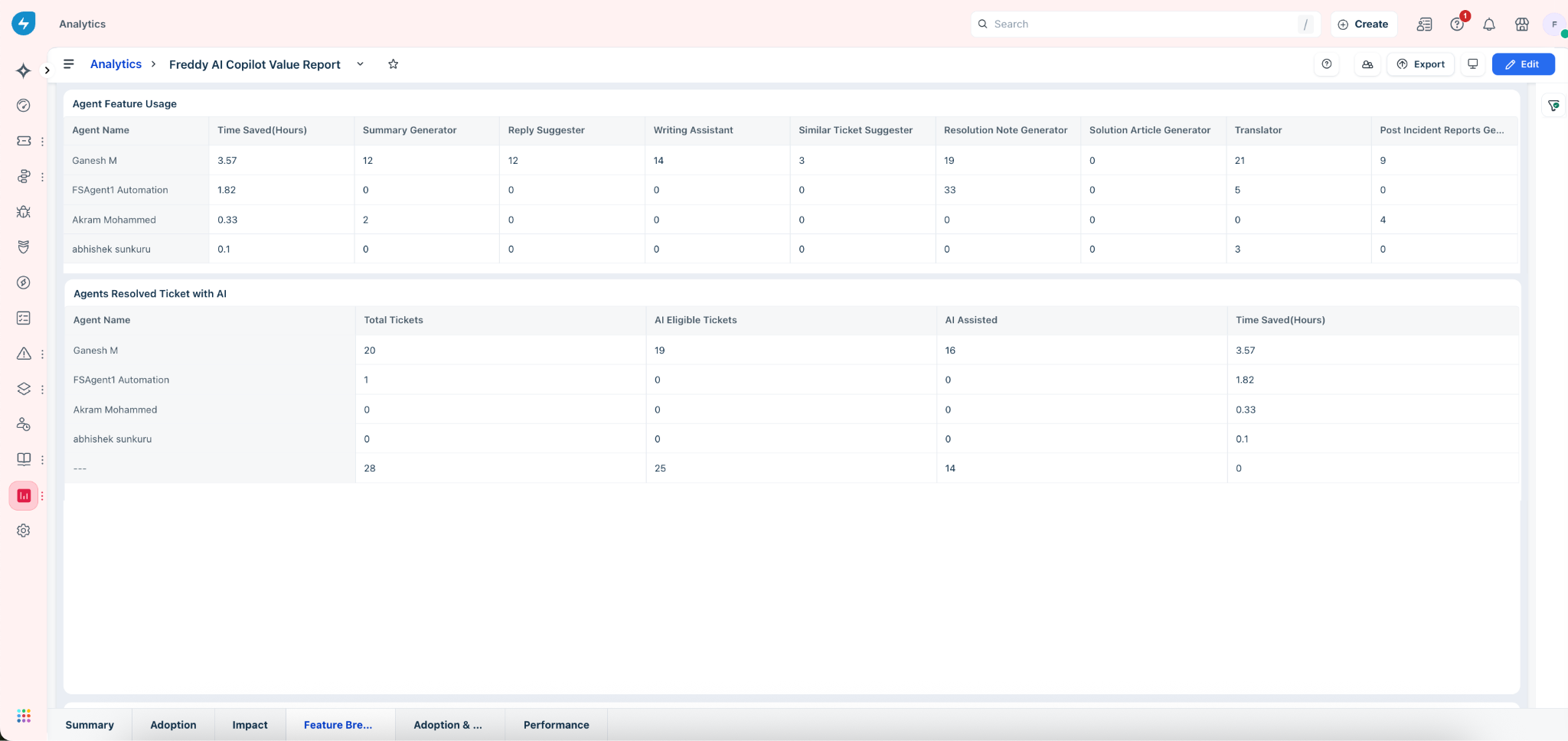
Features Used by Agents
Which agents are using which tools — and how much time are they saving? This table maps each agent's usage count across every Copilot feature alongside their total time saved, making it easy to spot both breadth of adoption and individual efficiency gains.
Key metrics in the table
| Column | What to look for |
| Time Saved (Hours) | Your per-agent efficiency headline — agents with high time saved but uneven feature usage may be over-relying on one or two tools. |
| Summary Generator, Reply Suggester, Writing Assistant | Core workflow features — low counts here suggest the agent hasn't integrated AI into their day-to-day ticket handling. |
| Similar Ticket Suggester, Resolution Note Generator | Secondary features that indicate deeper Copilot engagement — adoption here signals an agent moving beyond basics. |
| Solution Article Generator, Translator, Post Incident Reports | Advanced or situational features — usage depends on role and ticket type, so benchmark within relevant agent groups rather than across the board. |
``` Tip: Agents with zero usage across all features but a non-zero Time Saved value may have indirect AI exposure through automation rules. Validate whether these agents need hands-on onboarding or are already benefiting passively. ```
Tickets Resolved with AI
How effectively is each agent converting AI-eligible tickets into AI-assisted resolutions? This table reveals the gap between opportunity and actual usage at the individual level, making it your primary tool for targeted coaching conversations.
Key metrics in the table
| Column comparison | What to look for | Action |
| AI Eligible Tickets vs. AI Assisted | Agents with a high eligible count but low assisted count are leaving AI value on the table | Schedule a one-on-one enablement session to identify and remove workflow blockers |
| Total Tickets vs. AI Eligible Tickets | A large gap indicates a significant portion of the agent's workload falls outside Copilot's current scope | Review ticket type configuration to expand AI eligibility where possible. Where demand exceeds current capacity, consider purchasing additional licenses to widen access. |
| Time Saved (Hours) | Agents with AI-assisted tickets but low time saved may be accepting suggestions without meaningful workflow integration | Observe their ticket-handling workflow and identify where AI steps can be better embedded |
``` Tip: Sort by AI Assisted to immediately identify agents at the bottom of the list. Cross-reference with the Agent Feature Usage table above — agents with zero AI-assisted tickets and zero feature usage are your highest-priority targets for direct outreach and hands-on training. ```
Feature Usage (With Feedback)
This tab pairs feature-level adoption metrics with direct agent feedback, giving you a side-by-side view of how frequently each AI tool is being accepted and whether agents are signaling satisfaction or dissatisfaction with its suggestions. Use this view to prioritize which features need prompt tuning, additional training, or broader rollout.
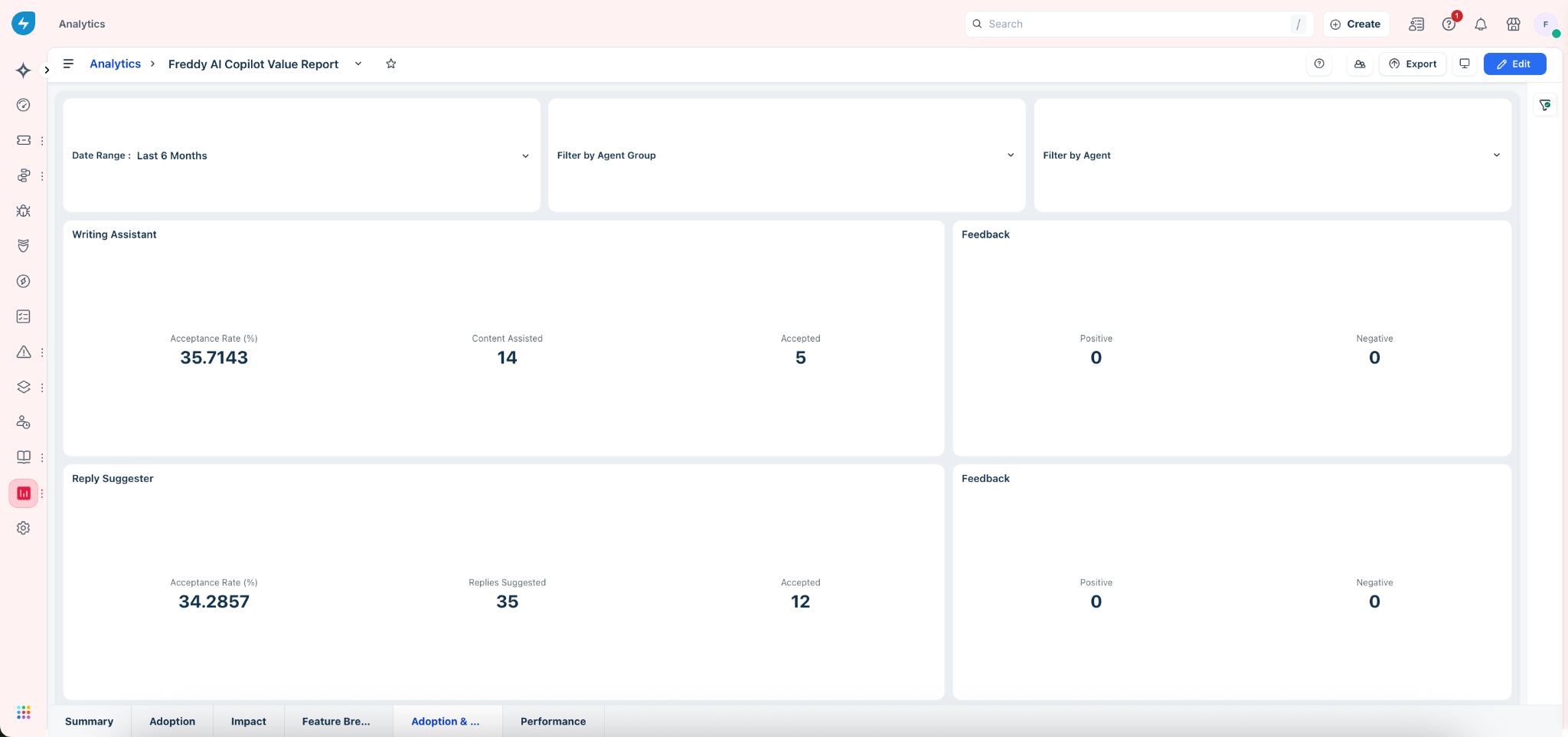
Reading each feature card
Each feature is presented as a pair — usage metrics on the left, feedback signals on the right. Together they tell a complete story: a high acceptance rate with no feedback may indicate passive usage, while a low acceptance rate with negative feedback points to a feature that needs attention.
Key metrics in the table
| Metric | What it means |
| Acceptance Rate (%) | The percentage of AI suggestions that agents actively accepted. This is your primary signal of whether the feature is generating useful, contextually relevant output. |
| Suggestions / Content / Notes Generated | The total number of times the feature was triggered. A high count with a low acceptance rate indicates the feature is being surfaced frequently but not trusted. |
| Accepted | The raw count of accepted suggestions. Track this alongside the rate to understand both quality and volume of value delivered. |
| Positive Feedback | Agents who explicitly marked a suggestion as helpful — a strong signal that the feature is meeting expectations for that ticket type. |
| Negative Feedback | Agents who explicitly marked a suggestion as unhelpful — a direct indicator that prompt quality, tone, or relevance needs improvement for that feature. |
``` Tip: Features with zero positive and zero negative feedback are not necessarily underperforming — agents may simply not be using the feedback mechanism. If acceptance rates are healthy but feedback is absent, introduce a team norm around rating suggestions to build a richer signal over time. ```
Feature Usage (Without Feedback)
While the Feature Usage tab reflects agent sentiment and usage trends, this tab shifts the lens to objective performance. It shows how each Copilot feature is actually doing its job, measured by generation counts, acceptance rates, and feature-specific output metrics — independent of user feedback.
Reading each feature card
Each card surfaces three metrics that together reveal the operational health of that feature. Use them to benchmark individual tools against each other and track improvement over time.
Key metrics in the table
| Metric | What it means |
| Acceptance Rate (%) | The share of generated outputs that agents accepted without discarding — your primary indicator of output quality and relevance for that feature. |
| Output Count (Summaries / Reports / Cues / Translations generated) | The total volume of AI outputs produced. High volume with low acceptance points to a feature being triggered frequently but not trusted. |
| Accepted | The raw count of accepted outputs — use this alongside the rate to understand both quality and absolute value delivered. |
``` Tip: Features with a high acceptance rate but low output volume — like Translator — are performing well but underutilized. Features with high output volume but low acceptance rate — like Ticket Summary — are your highest-leverage tuning opportunities: small improvements to output quality here will have an outsized effect on overall AI value delivered. ```